About Agent Search
Agent Searchの仕組みとGoogle技術を採用する理由
検索技術と生成AIを融合した Agent Search の仕組みと、SiteAsk がその基盤を採用する理由を整理します。
Agent Searchとは - 検索技術と生成AIの融合
Agent Searchとは、Googleの高度な検索技術と、最新の大規模言語モデル(LLM)を組み合わせた「検索特化型エージェント」です。
従来のサイト内検索は、ユーザーが入力したキーワードの一致を判定するものでした。これに対しAgent Searchは、Webサイト内の情報をAIがリアルタイムで探索・解析し、ユーザーの意図に沿った「回答」を生成するエージェントとして機能します。
Googleの検索技術を基盤に選択した理由
Webサイト上の膨大なデータ(テキスト、PDF、構造化データ)を最も正確に、かつ高速にクロールし、インデックス化できるのはGoogle検索の技術です。
SiteAskは、検索・回答生成にAgent Searchのインフラを直接活用することで、情報の網羅性と抽出精度を実現しています。
Googleカスタム検索(Custom Search JSON API)終了に伴う後継としての位置付け
長年、サイト内検索の標準として利用されてきた「Custom Search JSON API」はサービスの終了がアナウンスされています。2026年1月、新規の利用受付はすでに停止しており、既存のユーザーについても、2027年1月1日までの移行がGoogle公式により推奨されています。Agent Searchは、サイト内検索の最適な代替手段として紹介されています。
Agent Searchが回答を生成するプロセス
Agent Searchは、ユーザーの問いに対して以下の3つのプロセスを数秒のうちに実行します。
- 検索文言の解析
ユーザーの曖昧な入力文を解析し、検索に最適な質問へ変換します。主語の補完や用語の読み替えを行います。
- 情報の抽出
最適化されたクエリに基づき、サイト全体から関連性の高い情報の断片(チャンク)を複数特定します。特定のページだけでなく、サイトを横断して根拠となる情報を集約します。
- 回答の生成
抽出された情報の断片をAIが読み込み、回答を生成します。情報の優先順位を判断し、最も確度の高い回答を構成します。
回答には情報元となったページのリンクが付帯し、チャット利用者は根拠となったページへ回遊できます。

ハルシネーションを防ぎ、正確に回答できる理由
1. 自然言語の質問を的確に解釈する
ユーザーが入力する質問は、サイト内の用語や正式名称と一致するわけではありません。Agent Searchは、曖昧な表現や話し言葉による質問を、AIが内部で「検索に適したクエリ」へと動的に言い換え・拡張を行います。
ユーザーの知識レベルや語彙力に依存することなく、安定した検索結果を得ることができます。
2. セマンティック検索により適切な情報源を探す
整理されたクエリに基づき、単語の表面的な一致ではなく意味の類似性で情報を探索するセマンティック検索を実行します。
言葉をベクトル(数値)化して処理することで、例えば「料金」と「コスト」、「使いかた」と「操作手順」といった、表現は異なるが文脈が同じ情報を関連データとして引き当てます。従来のキーワード検索では辿り着けなかった「埋もれた正解」を、サイト全域から高精度に特定します。
3. グラウンディングによる根拠の固定
生成AIが持つ一般的な知識ではなく、「サイト内の公式コンテンツ」のみを情報元として回答を構成します。
サイト内に根拠となる情報が存在しない場合は、憶測で答えず情報がない旨を正しく回答するよう制御されています。競合サービス・企業に関する情報、転載された古い情報、推論に基づいた創作といった回答が発生することがありません。
そもそもの仕組みから「ハルシネーション(AIがつくもっともらしい嘘)」を未然に防ぎ、サイト上に設置する公式ツールにふさわしい回答の品質を担保しています。
Agent Searchによる自動RAG構築の仕組み
Agent Searchは、初期導入・導入後いずれにおいてもメンテナンスコストが極小化されています。
自動RAG構築
一般的なRAG(Retrieval-Augmented Generation)の構築には、データのクレンジング、チャンクサイズの最適化、メタデータ付与といった膨大な手作業が不可欠でした。
Agent Searchは、この複雑なプロセスを「URLの読み込み」から始まる一連の自動化フローへと置き換えています。
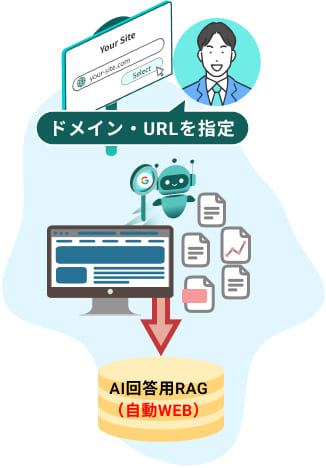
1. 対象ドメイン・URLの指定
管理画面から対象となるWebサイトのドメインや特定のURLを入力します。これにより、Agent Searchのクローラーが探索範囲を即座に認識します。個別にドキュメントをアップロードする手間は不要です。
2. Googleを活用した高速クロール
Googleの検索で使用されているクローラーが、サイト内のテキスト、階層構造、リンクされたPDFファイルまでを網羅的にスキャンします。
人間がデータの構造を整理し直す必要はなく、Webサイトの現状をそのまま「知識源」として取り込みます。
3. 自律的なデータ解析とベクトル化
収集されたデータは、AIが文脈や意味のまとまり(チャンク)を判断して自動的に分割します。同時に、それらの情報を多次元のベクトルデータに変換し、Agent Search専用のデータベースに格納します。このプロセスにより、キーワードの一致ではなく「意味の類似性」による高速な検索準備が整います。
4. サイト更新への自動追従
Webサイトが更新されると、Agent Searchはその変更を自動的に検知・同期します。情報の鮮度を保つための再学習作業やデータの手動アップロードは必要ありません。
サイト外や会員向けコンテンツも追加できる
Googleクラウド上に配置したプライベートなストレージを自動RAG構築の対象として追加できます。サイト上には公開していないドキュメントや、ログインが必要なサイトのソースコードなどを配置することで、サイトには公開されていない情報も回答に取り込むことができます。 ※ストレージの追加はPrivateプラン、On-Premiseプランでご利用いただけます。
企業やサイトに応じた回答の最適化
Agent Searchは、回答生成の傾向や会話トーンをビジネス目的に合わせてカスタマイズできます。
正確性とエビデンスを最優先する要約型
正確性とエビデンスを最優先します。回答の根拠となったページへのリンクを明示し、ユーザーが一次情報へスムーズに遷移できる導線を確保します。
- 適したニーズ:巨大なサイトから適切な情報を取得してほしい
- サイトの例:企業サイト、製品・サービス紹介サイト
コンバージョンを促す対話重視の接客型
ブランドイメージに合わせた口調で、ユーザーの関心を高める対話を行います。単なる回答にとどまらず、バナーの掲載によるネクストアクションを促す調整ができます。
- 適したニーズ:サービス理解を促進し、コンバージョンに繋げたい
- サイトの例:製品・サービス紹介サイト、オウンドメディア
SiteAskがもたらす価値
SiteAskのAgent Searchは、既存のサイト内検索の代替ではありません。
「探す」というストレスを「対話」によって解消することで、Webサイトに「自ら考え、回答するアクティブな接客面」という新しい機能をプラスします。
SiteAskでは、Agent Searchの高度な検索技術を、特別な専門知識なしに、タグ一つで実装できる周辺システムを擁しています。